Hacking native ARM64 binaries to run on the iOS Simulator - the dynamic framework edition
a 9 minute read by Bogo GiertlerNOTE:(bogo) This article focuses on dynamic libraries. This is a follow up to a separate article explaining how to run ARM64 static libraries on the iOS Simulator.
Since I published the original ARM64 hacking article, a couple of folks reached out asking whether a similar technique can be applied to dynamic frameworks, such as PSPDFKit or Google’s Interactive Media Ads SDK.
My original project did not account for the existence of dynamic frameworks, so hacking them seemed like a great learning opportunity. In the process, I found out that making a typical ARM64 dylib run in the iOS Simulator is actually pretty straightforward - and requires significantly less Mach-O acrobatics than a static library!
🧑🔬 Static vs Dynamic
Just like static libraries we were dealing with last week, dynamic libraries are used as a form of code sharing. The core difference lies in the linking process. Static libraries are linked in (by ld) at build time and become an integral part of the application’s binary. Dynamic libraries are linked in (by dyld3) at runtime and (theoretically) can be swapped out at any time - even after the application launches.
On Apple platforms, this is particularly useful for applications that provide multiple extensions. The developer, instead of shipping the same code and assets in each target, can bundle the shared content into a single framework and then link any binary in the application bundle against it.
In case of a large application, the space savings can easily go into hundreds of megabytes. An online tool called Emerge provides an interesting visualization for the Dropbox app - with eight distinct appexes, the Dropbox app bundle remains reasonably sized thanks to the (rather chonky) DropboxExtensions dynamic framework:
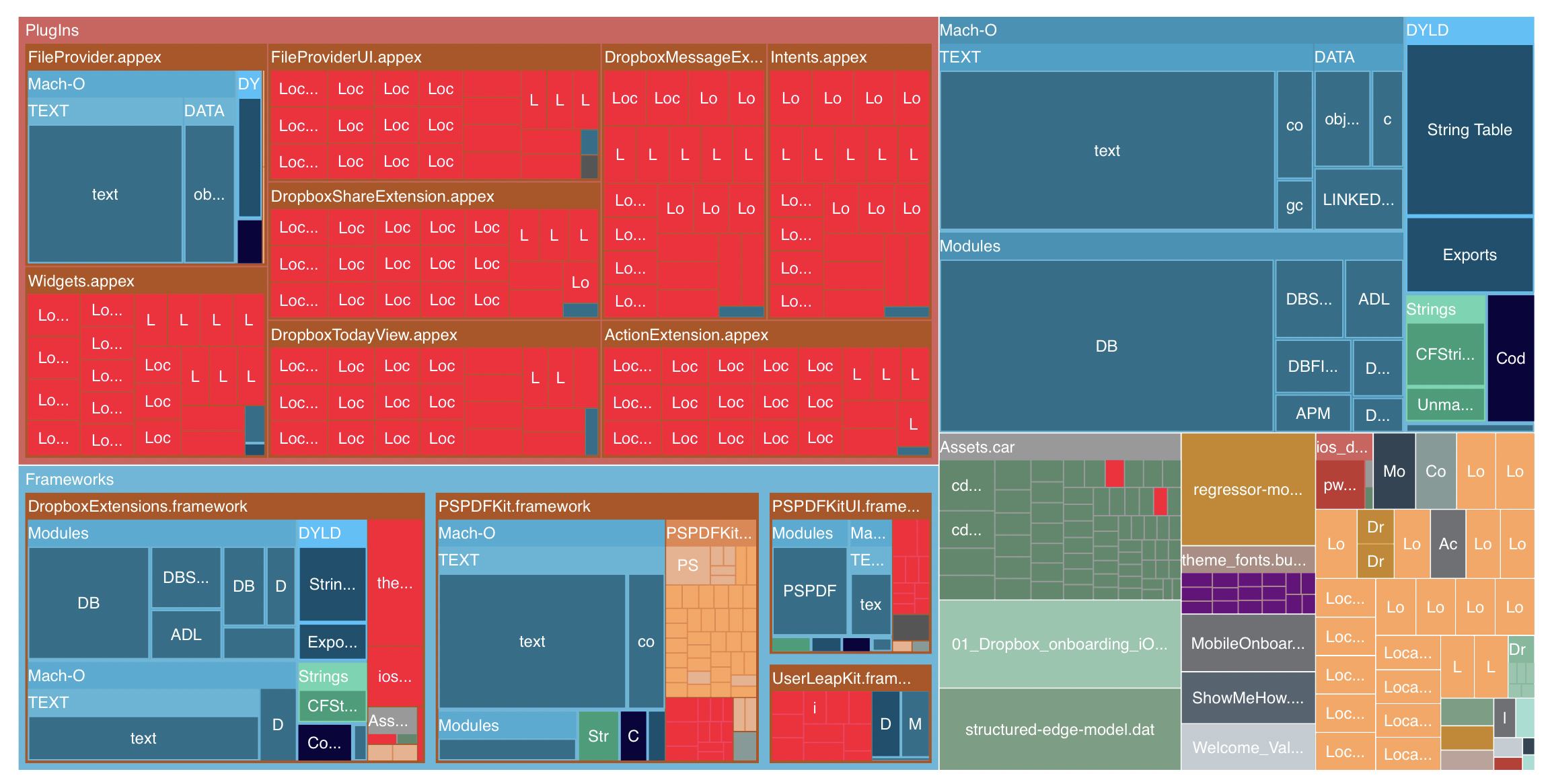
While dynamic libraries can seem like a silver bullet for modularizing a complex application, their loading incurs a significant cost at launch time and Apple advises developers to keep the total number of dylibs to a bare minimum of “a few”.
Under the hood, dynamic libraries are bona fide Mach-O fat binaries. Unlike the fat archives we worked with last week, our dynamic library begins with CAFE BABE - the magic number of Mach-O fat binary - and not the !<arch>.
$ od -N 4 -t x1 Example.framework/Example
0000000 ca fe ba be
All of this means we might be equipped to handle the dynamic libraries with a few simple modifications to our arm64-to-sim transmogrifier!
✨ My God, it’s full of 0s!
We start by lipo-ing the framework down to ARM64:
$ lipo -thin arm64 Example.framework/Example -output Example.framework/Example.arm64
$ od -N 4 -t x1 Example.framework/Example.arm64
0000000 cf fa ed fe
Let’s read this ARM64 slice with otool -fahl. We can immediately notice that, unlike in a typical static binary, LC_SEGMENT_64s seem to partition the entire file. We can confirm it by taking look at filesize and fileoff parameters, since they are present only in the LC_SEGMENT_64s:
$ stat -f%z Example/Example.arm64
6645432
$ otool -l Example/Example.arm64 | grep -E "filesize | fileoff "
fileoff 0
filesize 851968
fileoff 851968
filesize 196608
fileoff 1048576
filesize 4816896
fileoff 5865472
filesize 779960
If we add all the filesize fields, our suspicion is confirmed:
$ stat -f%z Example/Example.arm64
6645432
$ otool -l Example/Example.arm64 | grep filesize | grep -Eo "(\d+)" | paste -sd+ - | bc
6645432
This means that our approach of offsetting the LC_SEGMENT_64 might not work at all - the load commands are likely accounted for in the first segment already. Let’s zoom out a bit and check what sections does the LC_SEGMENT_64 point at:
$ otool -l Example/Example.arm64
Load command 0
cmd LC_SEGMENT_64
cmdsize 952
segname __TEXT
vmaddr 0x0000000000000000
vmsize 0x00000000000d0000
fileoff 0
filesize 851968
maxprot 0x00000005
initprot 0x00000005
nsects 11
flags 0x0
Section
sectname __text
segname __TEXT
addr 0x0000000000007210
size 0x00000000000aa300
offset 29200
align 2^2 (4)
reloff 0
nreloc 0
flags 0x80000400
reserved1 0
reserved2 0
...
Interesting! The first section of the first segment (__text) seems to be very far into the file, at 0x7210 (== 29,200) bytes. That seems odd - we know from last week that load commands are usually much shorter. Let’s check if our gut is right by summing up the length of all load_commands:
$ otool -l Example/Example.arm64 | grep -E "cmdsize " | grep -Eo "(\d+)" | paste -sd+ -
| bc
4736
Wowza! This is indeed way shorter than the offset of __text. Let’s investigate this further and use xxd to look at what is our dynamic library hiding at 4,736 bytes…
$ xxd -s 4736 -l 256 Example/Example.arm64
00001288: 2600 0000 1000 0000 98f3 5900 800d 0000 &.........Y.....
00001298: 2900 0000 1000 0000 1801 5a00 0000 0000 ).........Z.....
000012a8: 1d00 0000 1000 0000 c066 6500 5012 0100 .........fe.P...
000012b8: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000012c8: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000012d8: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000012e8: 0000 0000 0000 0000 0000 0000 0000 0000 ................
000012f8: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00001308: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00001318: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00001328: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00001338: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00001348: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00001358: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00001368: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00001378: 0000 0000 0000 0000 0000 0000 0000 0000 ................
A massive amount of completely empty load command padding! This is excellent news. Since this pre-existing padding must be already accounted for in all the load commands, we can use it to store the “excess” bytes caused by replacing LC_VERSION_MIN_IPHONEOS with LC_BUILD_VERSION.
To that end, let’s edit our previous week’s sources to “chomp” off the 8 bytes after the load commands. Since the zeros are not a part of load commands, our existing code reads them into programData variable using the readToEnd() function on the FileHandle object. To effectively overwrite the 8 bytes we need to fit the new command in, we simply seek ahead before that final read:
// discard the empty 8 bytes that we will use for our longer load command
let bytesToDiscard = abs(MemoryLayout<build_version_command>.stride - MemoryLayout<version_min_command>.stride)
_ = handle.readData(ofLength: bytesToDiscard)
Since we do not have to reconstruct any offsets in the binary, we also don’t need to handle any other load command updates. We can safely remove them from our map(), obviously except for the build_version_command substitution.
🪄 The vtool Way
Turns out there is a second solution, that is both significantly easier and does away with most of the shell-fu above - the vtool!
vtool was shipped by Apple as a part of the Xcode 11’s command line tools. While it appears to be meant to help in notarizing pre-macOS 10.9 frameworks, we can use its ability to edit load commands for our purposes as well.
vtool does not require us to perform any lipo, as it operates directly on the specified platform slice. Let’s first use it to check what are the relevant load commands in the file:
$ xcrun vtool -arch arm64 \
-show \
Example.framework/Example
Example.framework/Example (architecture arm64):
Load command 9
cmd LC_VERSION_MIN_IPHONEOS
cmdsize 16
version 8.0
sdk 14.0
Load command 10
cmd LC_SOURCE_VERSION
cmdsize 16
version 0.0
Great, we can see our old friend, LC_VERSION_MIN_IPHONEOS. Since we know that LC_BUILD_VERSION is 8 bytes longer, let’s see if the binary has enough padding space to accommodate it:
$ xcrun vtool -arch arm64 \
-show-space \
Example.framework/Example
Example.framework/Example (architecture arm64):
Mach header size: 32
Load command size: 4736
Available space: 24432
Total: 29200
Great! We seem to have 24,432 bytes of available space - all the 0s we saw using xxd. That’s plenty for our substitution.
$ xcrun vtool -arch arm64 \
-set-build-version 7 13.0 13.0 \
-replace \
-output Example.framework/Example.reworked \
Example.framework/Example
Let’s break this command up a little.
With -set-build-version and -replace parameters, we are asking vtool to set us up with a new LC_BUILD_VERSION and replace the previous LC_VERSION_MIN_IPHONE_OS entry. Should we not specify -replace, we will actually end up with both load commands present in the Mach-O header and compile- and run-time hilarity will ensue.
The build-version is specified as a <platform> <minos> <sdk> tuple. Note that vtool does not take a string for the platform value - the seemingly random number 7 in our invocation actually represents the IOSSIMULATOR entry in XNU’s Mach-O loader.
Let’s wrap this up by confirming that vtool modified the binary correctly:
$ xcrun vtool -arch arm64 \
-show \
Example.framework/Example.reworked
Example.framework/Example.reworked (architecture arm64):
Load command 9
cmd LC_SOURCE_VERSION
cmdsize 16
version 0.0
Load command 34
cmd LC_BUILD_VERSION
cmdsize 24
platform IOSSIMULATOR
minos 13.0
sdk 13.0
ntools 0
🔑 Keys to the Kingdom
After we run our modified transmogrifier, we will need to follow the familiar steps of lipo-ing the resulting ARM64 dylib with an x86 slice and assembling the library into an XCFramework. Should we use the vtool approach, we won’t even have to lipo the library back. (although thinning it to just the relevant platforms is a reasonable move)
In either case, following a straightforward framework substitution in the original Xcode project, the build should succeed!
Unfortunately, it’s not time to celebrate just yet - with linking happening at runtime, our app will almost certainly crash immediately after the Simulator boots. Xcode’s debugger console should contain a cryptic message similar to the one below:
dyld: Library not loaded: @rpath/Example.framework/Example
Referenced from: <snip>/Example.app/Example
Reason: no suitable image found. Did find:
<snip>/Example.framework/Example: code signature in (<snip>/Example.framework/Example) not valid for use in process using Library Validation: Trying to load an unsigned library
It appears that M1 Macs have a stricter policy on dynamic library validation compared to the Intel ones - and they won’t load an unsigned ARM64 library into memory, even if we mark it in Xcode as Embed & Sign. Luckily, we can fix that pretty easily:
$ xcrun codesign --sign - Example.xcframework/ios-arm64-x86_64-simulator/Example.framework/Example
Let’s try to run the app again…
Voilà, a native dynamic framework running on the iOS Simulator! 🎉
🤓 Learnings and Dead Ends
It took me a total of an hour to come up with this solution. Along the way I understood:
- that header padding is a typical practice in dylibs - every third party dynamic framework I looked had at least a few hundred bytes of ✨ 0s ✨ immediately following the load commands;
- that
vtoolis exactly the tool I needed for my ARM64 hacking - but it also requires binaries built with load command padding¯\_(ツ)_/¯; - that LIEF and macho-ruby were meant for handling dylibs - they both required padding after load commands to be able to edit the binary;
- that some dynamic libraries contain
LC_ENCRYPTION_INFOload command; fortunately, the encryption is not sensitive to changes to the padding, and our hacks continue to work.
🤓 Future Improvements
A couple of potential improvements are left as an exercise to the reader. These could be:
- exploring the impact of the
LC_CODE_SIGNATUREproperty, used by a few third party frameworks (e.g. PSPDFKit) - I have not tested yet whether it impacts binary edits like the one described in this article; - heuristic for detecting the header padding - it would be a neat feature to include in
arm64-to-sim, making it a one-stop shop for ARM64 transmogrification.
🙌 References
A couple of people and projects deserve special thanks:
- myeyesareblind on Twitter suggested using
vtoolto edit load commands - and it turned out to be just the right tool for the job, as long as padding is available! - Samantha Demi wrote a great explainer on the differences between static and dynamic frameworks and I’d recommend it to anyone looking to make sense of the topic;
- the Julia project seems to have run into the code signing issue on M1s as well, which confirmed the use of
codesignto solve the issue; - Allegro’s Kamil Borzym ran a series of benchmarks in 2018 to confirm that excessive loading of dylibs indeed carries a performance penalty at launch time;
- Louis Gerbarg gave a fantastic WWDC17 presentation on
dyld3and it’s still a worthy watch, 4 years on.